백엔드 개발의 기본 소양인 SQL을 작성하는 실력은 뛰어날 수록 더할 나위 없다.
실제로 대규모 트래픽이 발생하는 서비스에서는 이 성능을 매우 중요시 하는데,
일반적인 환경에서는 DB 조회적 측면에서 큰 성능 개선을 이끌 수 있으므로, 가장 기본이 되는 개선 방안이라고들 한다.
SQL을 공부하고, JPA 를 공부하며 항상 빠질 수 없는 얘기, 성능 최적화.
항상 고민하다가 개선을 할 수 있는 기회가 주어졌고, 공부한 내용을 바탕으로 내 생각과 결과를 정리해보겠다.
DB ERD Model
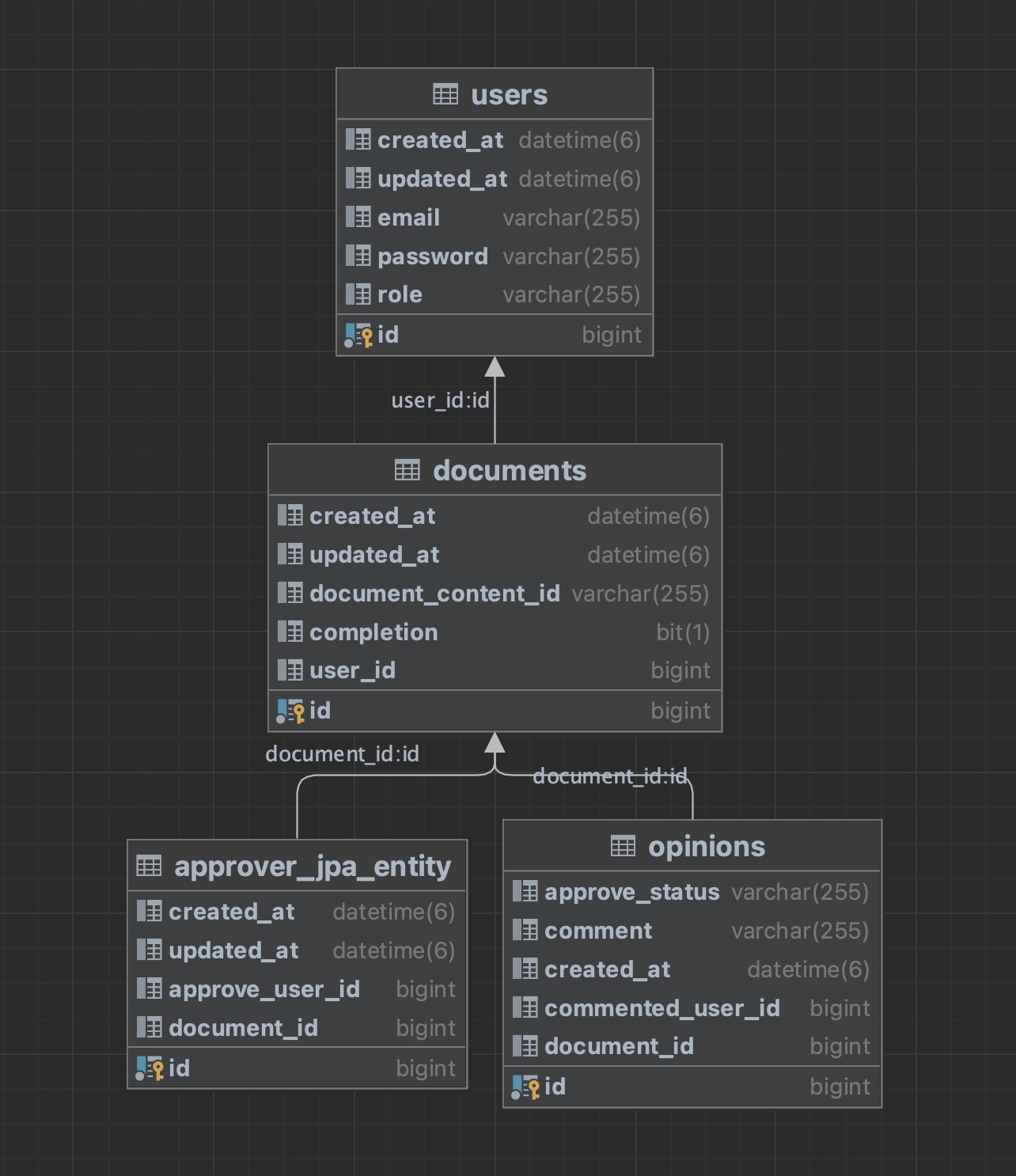
opnions entity를 paging 처리해서 여러 개를 뽑아야 하는 상황.
주어진 중요 파라미터는 user_id 뿐이다.
1. 보통 같으면 Document Entity를 먼저 조회한 후,
opinions 를 페이징 조회할 수 있겠다는 생각을 기본적으로 할 것이다.
그럼 쿼리가 두번 발생한다.
2. 한번에 묶어서 한방 쿼리로 조회할 수 있지 않을까?
=> join으로 해결하면 된다.
보통은 서브쿼리를 생각하는데, Mysql 을 사용한다면 inno db engine 이 아직은 서브 쿼리가 그렇게 최적화 되어 있지 않기 때문에 join 을 통해 해결하는 것이 좋다.
JPQL 을 사용하기 때문에, 객체 그래프 탐색이 가능하며 프로퍼티들을 호출해 조건문을 달면 된다.
그 결과를 한번 살펴보자.
결과
1. 전자의 방법대로 join을 사용하지 않고, 각각의 쿼리를 날렸을 경우
=> 쿼리가 두번 발생했다.

2. 후자의 방법대로 부모까지 join 해서 한방 쿼리를 날렸을 경우
=> 쿼리가 한번만 발생한다.
=> 시간 감소가 확연하다.
데이터의 개수가 20개 단위였고, 그 중에서 size가 3개인 paging 처리 쿼리인데도, 이렇게 차이났다.
100개, 1000개, 100000개 단위로 불어나면 차이는 커질 것이다.
앞으로 GET 관련 API의 성능 최적화는 DB 조회에서부터 시작하며 유의미한 성과를 거둘 수 있을 거라 생각한다.
'📗 JPA' 카테고리의 다른 글
| MapStruct! JPA Entity 매핑 간 주의해서 사용하자 (0) | 2024.03.24 |
|---|---|
| JPA 집계함수 sum 은 long 을 반환한다. (0) | 2023.07.26 |
| [Spring Data JPA] JPA Enum 필드에 관한 문제 (1) | 2023.02.21 |
| [Spring Data JPA] Transaction 없이 읽기 (0) | 2023.01.30 |
| JPA 개념 정리 (0) | 2022.07.15 |

